A: Как восстановить файл, некорректно принятый ReGet?
Менеджеры закачек очень популярны среди российских интернетчиков. Низкая скорость в купе с частными обрывами связи не оставляют никаких шансов скачать "тяжелый" файл за один раз. Но ведь не обязательно при очередном обрыве начинать скачивать файл с начала! Большинство серверов поддерживают позиционирование указателя текущей позиции чтения, позволяя в случае обрыва продолжить закачку с последнего прочитанного байта.
Однако, кроме обрывов связи и "падений трубки", случаются еще и сбои питания, привычные для всех зависания, от которых ReGet - популярный менеджер закачек – увы, не спасает. Если в момент "сливания" длинного файла неожиданный бросок напряжения приведет к выключению компьютера, "сливаемый" файл с большой степенью вероятности будет испорчен, – операционная система не успеет заполнить последний кластер, выделенный файлу, и в его хвосте окажется мусор! ReGet, не зная этого, продолжит закачку с последней позиции файла, "замуровав" "мусор" в его теле. Работать такой файл, разумеется, не будет.
Поэтому, после каждого сбоя (зависания, выключения питания) "мусорный хвост" приходится отрезать вручную. Для этой цели подходит утилита HIEW (Hacker's Viewer
– Хакерский Вьювер"), раздобыть последнюю версию которой можно у Сусликова Евгения – ее автора – sen@suslikov.kemerovo.su ss.
Загрузите "препарируемый" файл, указав его имя в командной строке, и, нажатием клавиши <F4> или <ENTER>, перейдите в hex-режим. Затем, с помощью "волшебной комбинации" <Ctrl-End> переместитесь в конец файла. Теперь необходимо отступить назад на величину кластера вашего диска (ее можно узнать, запустив программу проверки диска или заглянув в "свойства" диска) – нажмите <F5> и введите требуемое значение отступа в шестнадцатеричной нотации со знаком "минус". (Перевести десятичное число в шестнадцатеричное поможет калькулятор, встроенный в HIEW и вызываемый <All+'+'>). Переместившись на требуемую позицию, усеките файл комбинацией <F3>, <F10>. Теперь запустите ReGet, и он автоматически продолжит докачку с "безопасного" места.
Хуже, если требуется восстановить ранее скаченные файлы, содержащие мусор в середине. Сразу же возникают две проблемы – как определить где именно расположен мусор, и как заставить ReGet скачать фрагмент файла "от сих" – "до сих" для замены поверженного участка на новый?
Поиск сбойного фрагмента – самое сложное в операции восстановления. Отличить мусор от полезной информации, можно только зная структуру поверженного файла. С "текстовиками" никаких проблем нет – искомое место обнаруживаться визуальным просмотром, а вот как быть с остальными типами файлов? В результате серии экспериментов автором было установлено, что в мусоре присутствует по крайне мере одна регулярная структура – длинная цепочка из нескольких сотен нулей. Такая последовательность никогда не встречается в архивах и некоторых других типах файлов (например, pdf, rtf), поэтому она может служить своеобразной меткой – сигнатурой мусора. К сожалению, с другими форматами файлов дело обстоит сложнее, в частности, исполняемые файлы (в том числе и самораспакующиеся архивы) этими самыми нулевыми байтами могут быть напичканы под самую завязку – попробуй, разберись мусор это или нет!
Разберем для примера тривиальный случай. Допустим, при распаковке image4.zip (архив космических фотографий, взятый с http://stuma.simplenet.com/ds2000files/images4.zip) выдается ошибка извлечения файла "Inflating: EUROPA2.tif PKUNZIP: (W15) Warning! file fails CRC check"
Загрузим поврежденный архив в HIEW и попытаемся отыскать цепочку, состоящую более чем из десяти следующих друг за другом нулевых байт (<F7>, <Tab>, "00 00 00 00 00 00 00 00 00 00"):
Опаньки! Взгляните, что мы обнаружили!
002E6460: 68 D3 C9 38-16 B2 52 1E-B5 3F D3 0E-94 71 AE E4
002E6470: 5F DE 79 9F-99 E1 CD F9-56 D0 6A AC-64 37 F0 2D
002E6480: 00 00 00 00-00 00 00 00-00 00 00 00-00 00 00 00
002E6490: 00 00 00 00-00 00 00 00-00 00 00 00-00 00 00 00
002E64A0: 00 00 00 00-00 00 00 00-00 00 00 00-00 00 00 00
002E64B0: 00 00 00 00-00 00 00 00-00 00 00 00-00 00 00 00
002E64C0: 00 00 00 00-00 00 00 00-00 00 00 00-00 00 00 00
002E64D0: 00 00 00 00-00 00 00 00-00 00 00 00-00 00 00 00
002E64E0: 00 00 00 00-00 00 00 00-00 00 00 00-00 00 00 00
002E64F0: 00 00 00 00-00 00 00 00-00 00 00 00-00 00 00 00
002E6500: 00 00 00 00-00 00 00 00-00 00 00 00-00 00 00 00
002E6510: 00 00 00 00-00 00 00 00-00 00 00 00-00 00 00 00
002E6520: 00 00 00 00-00 00 00 00-00 00 00 00-00 00 00 00
002E6530: 00 00 00 00-00 00 00 00-00 00 00 00-00 00 00 00
002E6540: 00 00 00 00-00 00 00 00-00 00 00 00-00 00 00 00
002E6550: 00 00 00 00-00 00 00 00-00 00 00 00-00 00 00 00
002E6560: 00 00 00 00-00 00 00 00-00 00 00 00-00 00 00 00
002E6570: 00 00 00 00-00 00 00 00-00 00 00 00-00 00 00 00
002E6580: 00 00 00 00-00 00 00 00-00 00 00 00-00 00 00 00
002E6590: 00 00 00 00-00 00 00 00-00 00 00 00-00 00 00 00
002E65A0: 00 00 00 00-00 00 00 00-00 00 00 00-00 00 00 00
002E65B0: 00 00 00 00-00 00 00 00-00 00 00 00-00 00 00 00
002E65C0: 00 00 00 00-00 00 00 00-00 00 00 00-00 00 00 00
002E65D0: 00 00 00 00-00 00 00 00-00 00 00 00-00 00 00 00
002E65E0: 00 00 00 00-00 00 00 00-00 00 00 00-00 00 00 00
002E65F0: 00 00 00 00-00 00 00 00-00 00 00 00-00 00 00 00
002E6600: 10 A4 01 00-03 00 05 00-64 00 4C 8D-0C 01 00 01
002E6610: 00 06 00 CE-53 00 00 00-09 01 00 02-00 06 00 CB
Разумеется, крайне маловероятно, чтобы в архиве встретилась подобная последовательность (ведь архив это или что?). Вероятно, здесь-то и был застигнут ReGet врасплох сбоем питания или зависанием компьютера.
Подумаем, как можно наложить заплатку на "больное" место? Самое простое решение – обрезать искаженный файл немного выше начала цепочки нулей (вдруг сбой затронул и соседние участки?), запустить ReGet для докачки нескольких килобайт и дописать оставшийся от обрезания "хвост" в конец файла, чтобы не скачивать его заново из сети.
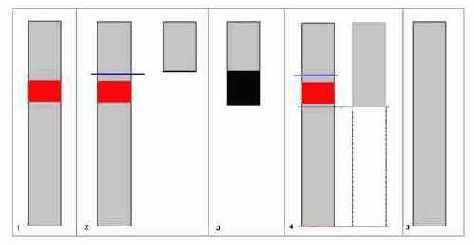
Рисунок 31 Рис. 0х026 Процедура восстановления поврежденного файла. Берем "больной" файл (1) – сбойный участок выделен красным ???, делаем его копию и отрезаем HIEW-ов чуть выше начала сбойного фрагмента (2), запускаем ReGet, чтобы он докачал столько килобайт, сколько составлял сбойный фрагмент плюс небольшой запас (3) – докаченный фрагмент выделен сплошной заливкой; дописываем неповрежденный хвост поврежденного файла к только что полученному (4) и в результате всех этих махинцаий имеем нормальный работоспособный файл (5).
Звучит заманчиво, но как все это выглядит на практике? Для начала создадим резервную копию испорченного файла, для чего воспользуемся любой привычной оболочкой или же командой copy из MS-DOS "Copy image4.zip back.me"
Теперь смело урежем оригинальный файл, поднявшись немного выше начала сбойного фрагмента (в HIEW-е это осуществляется нажатием <F3>, <F10>). Запускаем ReGet и терпеливо ждем пока десяток-другой килобайт не упадут на наш жесткий диск (ждать, очевидно, придется недолго).
Для определения границ сбоя и уверенности, что мы их гарантированно миновали, выполним побайтовое сравнение старого и нового файлов утилитой MS-DOS fc.exe: "Fc image4.zip back.me /b > log.txt". Заглянем в полученный файл log.txt
Сравнение файлов images4.zip
и back.me
002E6480: 33 00
002E6481: AA 00
002E6482: 31 00
002E6483: 0F 00
002E6484: FD 00
002E6485: EB 00
002E6486: D9 00
: : :
002E6607: 84 00
002E65F8: FB 00
002E65F9: 72 00
002E65FE9 00
002E65FB: 60 00
002E65FC: D7 00
002E65FD: 4E 00
002E65FE: C5 00
002E65FF: 3C 00
002E6600: C3 10
002E6601: CE A4
002E6602: A2 01
002E6603: 18 00
002E6604: 92 03
002E6605: 06 00
002E6606: 82 05
; ^^^^^^^ - последний байт сбоя
Оказывается, сбойный участок начинается с первого нулевого байта (байты, лежащие выше, совпадают в новой и старой версии), но вот за концом нулей находится некоторое количество искаженных байт, последний из которых расположен по смещению 0x2E6606.
Теперь остается дописать остаток "хвоста", взятого из резервной копии файла, что без труда можно сделать с помощью того же HIEW. Откроем резервный файл и переведем курсор на байт по смещению 0x236607 (<F5>, "236607") и, нажав звездочку на цифровой клавиатуре, выделим блок до конца файла. Затем еще раз звездочку для завершения выделения и <F2> для записи "хвоста" в укороченный файл.
Попробуем его распаковать: о, чудо! Это сработало! Простыми операциями нам удалось сэкономить уйму времени (и денег, кстати, тоже).
Конечно, ничего этого не потребовалось бы, будь ReGet устойчив к сбоям по питанию (как, например, GetRight – который всегда отрезает несколько килобайт от хвоста файла после каждого обрыва). Но, как знать, быть может, в следующих версиях это и будет исправлено?
Родственные вопросы:
Необходимо скачать большой файл, но соединение постоянно рвется, а сервер не поддерживает "докачки"… (следующий)
Попытка скачать с WEB-сервера файл моим любимым "качальщиком" заканчивается провалом – сервер "ругается" и не "отдает" файл. В то же время, через браузер все работает нормально, но, естественно, без докачки. Почему так?
